Table Of Contents
- 2.2.2. Python Examples using h5py
Previous topic
2.2.1. Example NeXus C programs using native HDF5 commands
Next topic
h5py example writing the simplest NeXus data file
2.2.1. Example NeXus C programs using native HDF5 commands
h5py example writing the simplest NeXus data file
One way to gain a quick familiarity with NeXus is to start working with some data. For at least the first few examples in this section, we have a simple two-column set of 1-D data, collected as part of a series of alignment scans by the APS USAXS instrument during the time it was stationed at beam line 32ID. We will show how to write this data using the Python language and the h5py package [1] (using h5py calls directly rather than using the NeXus NAPI). The actual data to be written was extracted (elsewhere) from a spec [2] data file and read as a text block from a file by the Python source code. Our examples will start with the simplest case and add only mild complexity with each new case since these examples are meant for those who are unfamiliar with NeXus.
| [1] | h5py: http://code.google.com/p/h5py |
| [2] | SPEC: http://certif.com/spec.html |
The data shown plotted in the next figure will be written to the NeXus HDF5 file using the only two required NeXus objects NXentry and NXdata in the first example and then minor variations on this structure in the next two examples. The data model is identical to the one in the Introduction chapter except that the names will be different, as shown below:

data structure, (from Introduction)
our h5py example
1 2 3 4 | /entry:NXentry
/mr_scan:NXdata
/mr : float64[31]
/I00 : int32[31]
|

plot of our mr_scan
two-column data for our mr_scan
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | 17.92608 1037
17.92591 1318
17.92575 1704
17.92558 2857
17.92541 4516
17.92525 9998
17.92508 23819
17.92491 31662
17.92475 40458
17.92458 49087
17.92441 56514
17.92425 63499
17.92408 66802
17.92391 66863
17.92375 66599
17.92358 66206
17.92341 65747
17.92325 65250
17.92308 64129
17.92291 63044
17.92275 60796
17.92258 56795
17.92241 51550
17.92225 43710
17.92208 29315
17.92191 19782
17.92175 12992
17.92158 6622
17.92141 4198
17.92125 2248
17.92108 1321
|
These two examples show how to write the simplest data (above). One example writes the data directly to the NXdata group while the other example writes the data to NXinstrument/NXdetector/data and then creates a soft link to that data in NXdata.
In the main code section of BasicWriter.py, a current time stamp is written in the format of ISO 8601. For simplicity of this code example, we use a text string for the time, rather than computing it directly from Python support library calls. It is easier this way to see the exact type of string formatting for the time. When using the Python datatime package, one way to write the time stamp is:
1 | timestamp = "T".join( str( datetime.datetime.now() ).split() )
|
The data (mr is similar to “two_theta” and I00 is similar to “counts”) is collated into two Python lists. We use our my_lib support to read the file and parse the two-column format.
The new HDF5 file is opened (and created if not already existing) for writing, setting common NeXus attributes in the same command from our support library. Proper HDF5+NeXus groups are created for /entry:NXentry/mr_scan:NXdata. Since we are not using the NAPI, our support library must create and set the NX_class attribute on each group.
Note
We want to create the desired structure of /entry:NXentry/mr_scan:NXdata/. First, our support library calls nxentry = f.create_group("entry") to create the NXentry group called entry at the root level. Then, it calls nxdata = nxentry.create_group("mr_scan") to create the NXentry group called entry as a child of the NXentry group.
Next, we create a dataset called title to hold a title string that can appear on the default plot.
Next, we create datasets for mr and I00 using our support library. The data type of each, as represented in numpy, will be recognized by h5py and automatically converted to the proper HDF5 type in the file. A Python dictionary of attributes is given, specifying the engineering units and other values needed by NeXus to provide a default plot of this data. By setting signal=1 as an attribute on I00, NeXus recognizes I00 as the default y axis for the plot. The axes="mr" connects the dataset to be used as the x axis.
Finally, we must remember to call f.close() or we might corrupt the file when the program quits.
BasicWriter.py: Write a NeXus HDF5 file using Python with h5py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | #!/usr/bin/env python
'''Writes a NeXus HDF5 file using h5py and numpy'''
import h5py # HDF5 support
import numpy
import my_lib # uses h5py
print "Write a NeXus HDF5 file"
fileName = "prj_test.nexus.hdf5"
timestamp = "2010-10-18T17:17:04-0500"
# load data from two column format
data = numpy.loadtxt('input.dat').T
mr_arr = data[0]
i00_arr = numpy.asarray(data[1],'int32')
# create the HDF5 NeXus file
f = my_lib.makeFile(fileName, file_name=fileName,
file_time=timestamp,
instrument="APS USAXS at 32ID-B",
creator="BasicWriter.py",
NeXus_version="4.3.0",
HDF5_Version=h5py.version.hdf5_version,
h5py_version=h5py.version.version)
nxentry = my_lib.makeGroup(f, "entry", "NXentry")
my_lib.makeDataset(nxentry, 'title', data='1-D scan of I00 v. mr')
nxdata = my_lib.makeGroup(nxentry, "mr_scan", "NXdata")
my_lib.makeDataset(nxdata, "mr", mr_arr, units='degrees',
long_name='USAXS mr (degrees)')
my_lib.makeDataset(nxdata, "I00", i00_arr, units='counts',
signal=1, # Y axis of default plot
axes='mr', # name "mr" as X axis
long_name='USAXS I00 (counts)')
f.close() # be CERTAIN to close the file
print "wrote file:", fileName
|
The file reader, BasicReader.py, is very simple since the bulk of the work is done by h5py. Our code opens the HDF5 we wrote above, prints the HDF5 attributes from the file, reads the two datasets, and then prints them out as columns. As simple as that. Of course, real code might add some error-handling and extracting other useful stuff from the file.
Note
See that we identified each of the two datasets using HDF5 absolute path references (just using the group and dataset names). Also, while coding this example, we were reminded that HDF5 is sensitive to upper or lowercase. That is, I00 is not the same is i00.
BasicReader.py: Read a NeXus HDF5 file using Python with h5py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #!/usr/bin/env python
'''Reads NeXus HDF5 files using h5py and prints the contents'''
import h5py # HDF5 support
fileName = "prj_test.nexus.hdf5"
f = h5py.File(fileName, "r")
for item in f.attrs.keys():
print item + ":", f.attrs[item]
mr = f['/entry/mr_scan/mr']
i00 = f['/entry/mr_scan/I00']
print "%s\t%s\t%s" % ("#", "mr", "I00")
for i in range(len(mr)):
print "%d\t%g\t%d" % (i, mr[i], i00[i])
f.close()
|
Output from BasicReader.py is shown next.
Output from BasicReader.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | file_name: prj_test.nexus.hdf5
file_time: 2010-10-18T17:17:04-0500
creator: BasicWriter.py
HDF5_Version: 1.8.5
NeXus_version: 4.3.0
h5py_version: 1.2.1
instrument: APS USAXS at 32ID-B
# mr I00
0 17.9261 1037
1 17.9259 1318
2 17.9258 1704
3 17.9256 2857
4 17.9254 4516
5 17.9252 9998
6 17.9251 23819
7 17.9249 31662
8 17.9247 40458
9 17.9246 49087
10 17.9244 56514
11 17.9243 63499
12 17.9241 66802
13 17.9239 66863
14 17.9237 66599
15 17.9236 66206
16 17.9234 65747
17 17.9232 65250
18 17.9231 64129
19 17.9229 63044
20 17.9228 60796
21 17.9226 56795
22 17.9224 51550
23 17.9222 43710
24 17.9221 29315
25 17.9219 19782
26 17.9217 12992
27 17.9216 6622
28 17.9214 4198
29 17.9213 2248
30 17.9211 1321
|
Now we have an HDF5 file that contains our data. What makes this different from a NeXus data file? A NeXus file has a specific arrangement of groups and datasets in an HDF5 file.
To test that our HDF5 file conforms to the NeXus standard, we use the Java-version of NXvalidate. Referring to the next figure, we compare our HDF5 file with the rules for generic [3] data files (all.nxdl.xml). The only items that have been flagged are the “non-standard field names” mr and I00. Neither of these two names is specifically named in the NeXus NXDL definition for the NXdata base class. As we’ll see shortly, this is not a problem.
| [3] | generic NeXus data files: NeXus data files for which no application-specific NXDL applies |

NeXus validation of our HDF5 file
Note
Note that NXvalidate shows only the first data field for mr and I00.
Now that we are certain our file conforms to the NeXus standard, let’s plot it using the NeXpy [4] client tool. To help label the plot, we added the long_name attributes to each of our datasets. We also added metadata to the root level of our HDF5 file similar to that written by the NAPI. It seemed to be a useful addition. Compare this with plot of our mr_scan and note that the horizontal axis of this plot is mirrored from that above. This is because the data is stored in the file in descending mr order and NeXpy has plotted it that way by default.
| [4] | NeXpy: http://nexpy.github.io/nexpy/ |
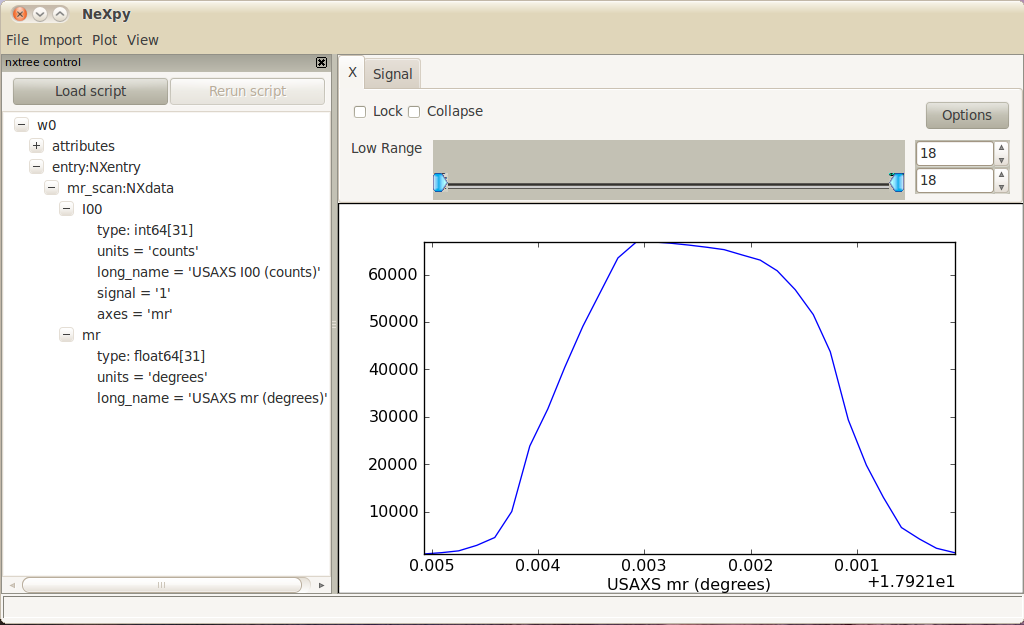
plot of our mr_scan using NeXpy
HDF5 files may contain links to data (or groups) in other files. This can be used to advantage to refer to data in existing HDF5 files and create NeXus-compliant data files. Here, we show such an example, using the same counts v. two_theta data from the examples above.
Take for example, the structure of external_angles.hdf5, a simple HDF5 data file that contains just the two_theta angles in an HDF5 dataset at the root level of the file. Although this is a valid HDF5 data file, it is not a valid NeXus data file:
1 2 | angles:float64[31] = [17.926079999999999, '...', 17.92108]
@units = degrees
|
The data in the file external_angles.hdf5 might be referenced from another HDF5 file (such as external_counts.hdf5) by an HDF5 external link. [5] Here is an example of the structure
1 2 3 4 5 6 7 8 | entry:NXentry
instrument:NXinstrument
detector:NXdetector
counts:NX_INT32[31] = [1037, '...', 1321]
@units = counts
@signal = 1
@axes = two_theta
two_theta --> file="external_angles.hdf5", path="/angles"
|
Note
The file external_counts.hdf5 is not a complete NeXus file since it does not contain an NXdata group containing a dataset with signal=1 attribute.
| [5] | see these URLs for further guidance on HDF5 external links: http://www.hdfgroup.org/HDF5/doc/RM/RM_H5L.html#Link-CreateExternal, http://www.h5py.org/docs-1.3/guide/group.html#external-links |
A valid NeXus data file could be created that refers to the data in these files without making a copy of the data files themselves.
Note
It is necessary for all these files to be located together in the same directory for the HDF5 external file links to work properly.`
To be a valid NeXus file, it must contain a NXentry group containing a NXdata group containing only one dataset with the aatribute signal=1. For the files above, it is simple to make a master file that links to the data we desire, from structure that we create. In external_counts.hdf5 above, see that the required attribute signal=1 is already present. Here is external_master.hdf5, an example:
1 2 3 4 5 | entry:NXentry
instrument --> file="external_counts.hdf5", path="/entry/instrument"
data:NXdata
counts --> file="external_counts.hdf5", path="/entry/instrument/detector/counts"
two_theta --> file="external_angles.hdf5", path="/angles"
|
Here is the complete code of a Python program, using h5py to write a NeXus-compliant HDF5 file with links to data in other HDF5 files.
externalExample.py: Write using HDF5 external links
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | #!/usr/bin/env python
'''
Writes a NeXus HDF5 file using h5py with links to data in other HDF5 files.
This example is based on ``writer_2_1``.
'''
import my_lib
FILE_INPUT = 'input.dat'
FILE_HDF5_MASTER = 'external_master.hdf5'
FILE_HDF5_ANGLES = 'external_angles.hdf5'
FILE_HDF5_COUNTS = 'external_counts.hdf5'
#---------------------------
# get some data
tthData, countsData = my_lib.get2ColumnData(FILE_INPUT)
# put the angle data in an external (non-NeXus) HDF5 data file
f = my_lib.makeFile(FILE_HDF5_ANGLES) # create an HDF5 file (non-NeXus)
tth = my_lib.makeDataset(f, "angles", tthData, units='degrees')
f.close() # be CERTAIN to close the file
# put the detector counts in an external NeXus HDF5 data file
f = my_lib.makeFile(FILE_HDF5_COUNTS)
nxentry = my_lib.makeGroup(f, 'entry', 'NXentry')
nxinstrument = my_lib.makeGroup(nxentry, 'instrument', 'NXinstrument')
nxdetector = my_lib.makeGroup(nxinstrument, 'detector', 'NXdetector')
counts = my_lib.makeDataset(nxdetector, "counts", countsData,
units='counts', signal=1, axes='two_theta')
# make a link since "two_theta" has not been stored here
my_lib.makeExternalLink(f, FILE_HDF5_ANGLES,
'/angles', nxdetector.name+'/two_theta')
f.close()
# create a master NeXus HDF5 file
f = my_lib.makeFile(FILE_HDF5_MASTER)
nxentry = my_lib.makeGroup(f, 'entry', 'NXentry')
nxdata = my_lib.makeGroup(nxentry, 'data', 'NXdata')
my_lib.makeExternalLink(f, FILE_HDF5_ANGLES,
'/angles', nxdata.name+'/two_theta')
my_lib.makeExternalLink(f, FILE_HDF5_COUNTS,
'/entry/instrument/detector/counts',
nxdata.name+'/counts')
my_lib.makeExternalLink(f, FILE_HDF5_COUNTS,
'/entry/instrument',
nxentry.name+'/instrument')
f.close()
|
Two additional Python modules were used to describe these h5py examples. The source code for each is given here. The first is a library we wrote that helps us create standard NeXus components using h5py. The second is a tool that helps us inspect the content and structure of HDF5 files.
The examples in this section make use of a small helper library that calls h5py to create the various NeXus data components of Data Groups, Data Fields, Data Attributes, and Links. In a smaller sense, this subroutine library (my_lib) fills the role of the NAPI for writing the data using h5py.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 | #!/usr/bin/env python
'''
my_lib: routines to support reading & writing NeXus HDF5 files using h5py
'''
import h5py # HDF5 support
import numpy # in this case, provides data structures
def makeFile(filename, **attr):
"""
create and open an empty NeXus HDF5 file using h5py
Any named parameters in the call to this method will be saved as
attributes of the root of the file.
Note that **attr is a dictionary of named parameters.
:param str filename: valid file name
:param attr: optional keywords of attributes
:return: h5py file object
"""
obj = h5py.File(filename, "w")
addAttributes(obj, attr)
return obj
def makeGroup(parent, name, nxclass, **attr):
"""
create a NeXus group
Any named parameters in the call to this method
will be saved as attributes of the group.
Note that **attr is a dictionary of named parameters.
:param obj parent: parent group
:param str name: valid NeXus group name
:param str nxclass: valid NeXus class name
:param attr: optional keywords of attributes
:return: h5py group object
"""
obj = parent.create_group(name)
obj.attrs["NX_class"] = nxclass
addAttributes(obj, attr)
return obj
def makeDataset(parent, name, data = None, **attr):
'''
create and write data to a dataset in the HDF5 file hierarchy
Any named parameters in the call to this method
will be saved as attributes of the dataset.
:param obj parent: parent group
:param str name: valid NeXus dataset name
:param obj data: the data to be saved
:param attr: optional keywords of attributes
:return: h5py dataset object
'''
if data == None:
obj = parent.create_dataset(name)
else:
obj = parent.create_dataset(name, data=data)
addAttributes(obj, attr)
return obj
def makeLink(parent, sourceObject, targetName):
"""
create an internal NeXus (hard) link in an HDF5 file
:param obj parent: parent group of source
:param obj sourceObject: existing HDF5 object
:param str targetName: HDF5 node path to be created,
such as ``/entry/data/data``
"""
if not 'target' in sourceObject.attrs:
# NeXus link, NOT an HDF5 link!
sourceObject.attrs["target"] = str(sourceObject.name)
parent._id.link(sourceObject.name, targetName, h5py.h5g.LINK_HARD)
def makeExternalLink(hdf5FileObject, sourceFile, sourcePath, targetPath):
"""
create an external link from sourceFile, sourcePath to targetPath in hdf5FileObject
:param obj hdf5FileObject: open HDF5 file object
:param str sourceFile: file containing existing HDF5 object at sourcePath
:param str sourcePath: path to existing HDF5 object in sourceFile
:param str targetPath: full node path to be created in current open HDF5 file,
such as ``/entry/data/data``
.. note::
Since the object retrieved is in a different file,
its ".file" and ".parent" properties will refer to
objects in that file, not the file in which the link resides.
.. see:: http://www.h5py.org/docs-1.3/guide/group.html#external-links
This routine is provided as a reminder how to do this simple operation.
"""
hdf5FileObject[targetPath] = h5py.ExternalLink(sourceFile, sourcePath)
def addAttributes(parent, attr):
"""
add attributes to an h5py data item
:param obj parent: h5py parent object
:param dict attr: dictionary of attributes
"""
if attr and type(attr) == type({}):
# attr is a dictionary of attributes
for k, v in attr.items():
parent.attrs[k] = v
def get2ColumnData(fileName):
'''
read two-column data from a file,
first column is float,
second column is integer
'''
buffer = numpy.loadtxt(fileName).T
xArr = buffer[0]
yArr = numpy.asarray(buffer[1],'int32')
return xArr, yArr
|
The module h5toText reads an HDF5 data file and prints out the structure of the groups, datasets, attributes, and links in that file. There is a command-line option to print out more or less of the data in the dataset arrays.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 | #!/usr/bin/env python
'''
Print the structure of an HDF5 file to stdout
'''
import h5py
import os
import sys
import getopt
class H5toText(object):
'''
Example usage showing default display::
mc = H5toText(filename)
mc.array_items_shown = 5
mc.report()
'''
filename = None
requested_filename = None
isNeXus = False
array_items_shown = 5
def __init__(self, filename, makeReport = False):
''' Constructor '''
self.requested_filename = filename
if os.path.exists(filename):
self.filename = filename
self.isNeXus = self.testIsNeXus()
if makeReport:
self.report()
def report(self):
''' reporter '''
if self.filename == None: return
f = h5py.File(self.filename, 'r')
txt = self.filename
if self.isNeXus:
txt += ":NeXus data file"
self.showGroup(f, txt, indentation = "")
f.close()
def testIsNeXus(self):
'''
test if the selected HDF5 file is a NeXus file
At this time, the code only tests for the existence of
the NXentry group. The tests should be extended to require
a NXdata group and a single dataset containing signal=1 attribute.
'''
result = False
try:
f = h5py.File(self.filename, 'r')
for value in f.itervalues():
#print str(type(value))
if '.Group' not in str(type(value)):
continue
#print value.attrs.keys()
if 'NX_class' not in value.attrs:
continue
v = value.attrs['NX_class']
#print type(v), v, type("a string")
possible_types = ["<type 'numpy.string_'>", ]
possible_types.append("<type 'str'>")
if str(type(v)) not in possible_types:
continue
if str(v) == str('NXentry'):
# TODO: apply more tests
# for group NXdata
# and signal=1 attribute on only one dataset
result = True
break
f.close()
except:
pass
return result
def showGroup(self, obj, name, indentation = " "):
'''print the contents of the group'''
nxclass = ""
if 'NX_class' in obj.attrs:
class_attr = obj.attrs['NX_class']
nxclass = ":" + str(class_attr)
print indentation + name + nxclass
self.showAttributes(obj, indentation)
# show datasets and links next
groups = []
for itemname in sorted(obj):
linkref = obj.get(itemname, getlink=True)
if '.ExternalLink' in str(type(linkref)):
# if the external file is not present, cannot know if
# link target is a dataset or a group or another link
fmt = '%s %s --> file="%s", path="%s"'
print fmt % (indentation, itemname, linkref.filename, linkref.path)
else:
classref = obj.get(itemname, getclass=True)
value = obj.get(itemname)
if '.File' in str(classref) or '.Group' in str(classref):
groups.append(value)
elif '.Dataset' in str(classref):
self.showDataset(value, itemname, indentation+" ")
else:
msg = "unidentified %s: %s, %s", itemname, repr(classref), repr(linkref)
raise Exception, msg
# then show things that look like groups
for value in groups:
itemname = value.name.split("/")[-1]
self.showGroup(value, itemname, indentation+" ")
def showAttributes(self, obj, indentation = " "):
'''print any attributes'''
for name, value in obj.attrs.iteritems():
print "%s @%s = %s" % (indentation, name, str(value))
def showDataset(self, dset, name, indentation = " "):
'''print the contents and structure of a dataset'''
shape = dset.shape
if self.isNeXus:
if "target" in dset.attrs:
if dset.attrs['target'] != dset.name:
print "%s%s --> %s" % (indentation, name,
dset.attrs['target'])
return
txType = self.getType(dset)
txShape = self.getShape(dset)
if shape == (1,):
value = " = %s" % str(dset[0])
print "%s%s:%s%s%s" % (indentation, name, txType,
txShape, value)
self.showAttributes(dset, indentation)
else:
print "%s%s:%s%s = __array" % (indentation, name,
txType, txShape)
# show these before __array
self.showAttributes(dset, indentation)
if self.array_items_shown > 2:
value = self.formatArray(dset, indentation + ' ')
print "%s %s = %s" % (indentation, "__array", value)
else:
print "%s %s: %s" % (indentation, "__array", "not shown")
def getType(self, obj):
''' get the storage (data) type of the dataset '''
t = str(obj.dtype)
if t[0:2] == '|S':
t = 'char[%s]' % t[2:]
if self.isNeXus:
t = 'NX_' + t.upper()
return t
def getShape(self, obj):
''' return the shape of the HDF5 dataset '''
s = obj.shape
l = []
for dim in s:
l.append(str(dim))
if l == ['1']:
result = ""
else:
result = "[%s]" % ",".join(l)
return result
def formatArray(self, obj, indentation = ' '):
''' nicely format an array up to rank=5 '''
shape = obj.shape
r = ""
if len(shape) in (1, 2, 3, 4, 5):
r = self.formatNdArray(obj, indentation + ' ')
if len(shape) > 5:
r = "### no arrays for rank > 5 ###"
return r
def decideNumShown(self, n):
''' determine how many values to show '''
if self.array_items_shown != None:
if n > self.array_items_shown:
n = self.array_items_shown - 2
return n
def formatNdArray(self, obj, indentation = ' '):
''' return a list of lower-dimension arrays, nicely formatted '''
shape = obj.shape
rank = len(shape)
if not rank in (1, 2, 3, 4, 5): return None
n = self.decideNumShown( shape[0] )
r = []
for i in range(n):
if rank == 1: item = obj[i]
if rank == 2: item = self.formatNdArray(obj[i, :])
if rank == 3: item = self.formatNdArray(obj[i, :, :],
indentation + ' ')
if rank == 4: item = self.formatNdArray(obj[i, :, :, :],
indentation + ' ')
if rank == 5: item = self.formatNdArray(obj[i, :, :, :, :],
indentation + ' ')
r.append( item )
if n < shape[0]:
# skip over most
r.append("...")
# get the last one
if rank == 1: item = obj[-1]
if rank == 2: item = self.formatNdArray(obj[-1, :])
if rank == 3: item = self.formatNdArray(obj[-1, :, :],
indentation + ' ')
if rank == 4: item = self.formatNdArray(obj[-1, :, :, :],
indentation + ' ')
if rank == 5: item = self.formatNdArray(obj[-1, :, :, :, :],
indentation + ' ')
r.append( item )
if rank == 1:
s = str( r )
else:
s = "[\n" + indentation + ' '
s += ("\n" + indentation + ' ').join(r)
s += "\n" + indentation + "]"
return s
def do_filelist(filelist, limit=5):
'''
interpret the structure of a list of HDF5 files
:param [str] filelist: one or more file names to be interpreted
:param int limit: maximum number of array items to be shown (default = 5)
'''
for item in filelist:
mc = H5toText(item)
mc.array_items_shown = limit
mc.report()
def do_test():
limit = 3
filelist = []
filelist.append('th02c_ps02_1_master.h5')
filelist.append('external_angles.hdf5')
filelist.append('external_counts.hdf5')
filelist.append('external_master.hdf5')
filelist.append('../Create/example1.hdf5')
filelist.append('../Create/example2.hdf5')
filelist.append('../Create/example3.hdf5')
filelist.append('../Create/example4.hdf5')
filelist.append('../../../NeXus/definitions/trunk/manual/examples/h5py/prj_test.nexus.hdf5')
filelist.append('../../../NeXus/definitions/exampledata/code/hdf5/dmc01.h5')
filelist.append('../../../NeXus/definitions/exampledata/code/hdf5/dmc02.h5')
filelist.append('../../../NeXus/definitions/exampledata/code/hdf5/focus2007n001335.hdf')
filelist.append('../../../NeXus/definitions/exampledata/code/hdf5/NXtest.h5')
filelist.append('../../../NeXus/definitions/exampledata/code/hdf5/sans2009n012333.hdf')
filelist.append('../Create/simple5.nxs')
filelist.append('../Create/bad.h5')
do_filelist(filelist, limit)
def main():
'''standard command-line interface'''
try:
opts, args = getopt.getopt(sys.argv[1:], "n:")
except:
print
print "usage: ", sys.argv[0], " [-n ##] HDF5_file_name [another_HDF5_file_name]"
print " -n ## : limit number of displayed array items to ## (must be 3 or more or 'None')"
print
for item in opts:
if item[0] == "-n":
if item[1].lower() == "none":
limit = None
else:
limit = int(item[1])
do_filelist(args)
if __name__ == '__main__':
if len(sys.argv) > 1:
main()
else:
do_test()
|